Scalability and Resilience: Learn How Appery.io Ensures API Express and Server Code On-demand Deployment
Appery.io had a strong 2016 and inches closer and closer to 400,000 developers. At the same time, the constant platform updates we roll out add more benefits, services, features, and options. Even without the constant updates, supporting a platform with so many developers would not be a simple task. Our platform has to be ready for continuous updates, increased load, and new user requests and requirements.
We want to provide high SLA level services and avoid unexpected slowdowns and downtimes for customers’ apps even during peak hours. To provide the required scalability and resilience, we rely on industry leader Amazon Web Services and its various features such as Auto Scaling, Launch Configurations, and CloudWatch.
In this blog post you will learn how exactly we ensure scalability and resilience for Appery.io API Express and Server Code services.
Appery.io is a cloud-based platform. The uptime must be 100%. Users must be able to access the platform to manage their apps and backend services. That’s, in essence, a high SLA level service. Our engineers understand this and we do our best to guarantee this required SLA for the Appery.io platform.
Handling General Load
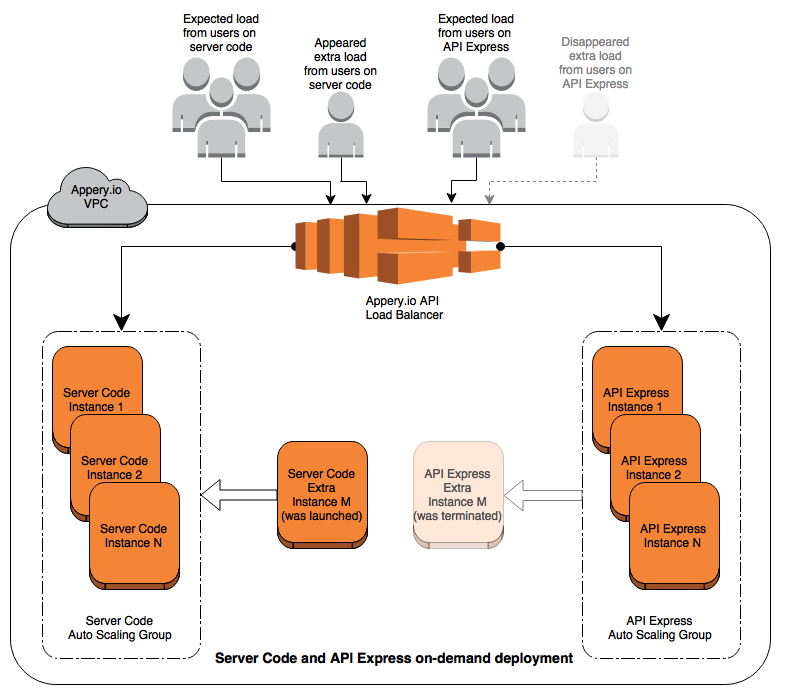
To make this happen we utilize Auto Scaling. We look at production environment logs and statistics in real-time to understand the current load on our API Express, Server Code, and other services.
We use a detailed forecast and have access to information about the allocation of incoming requests by day, weeks, and month. Using this information we can predict peak hours for the backend services and avoid degraded performance as high load impacts on services response time.
To ensure app performance is not impacted by extra requests to API Express or Server Code services, the platform automatically adjusts request capacity. The platform changes capacity for Auto Scaling groups (for this period), and new (extra) nodes with all the required setup and configuration are added (or removed) automatically from prepared Launch Configurations.
This mechanism also allows us to avoid downtime during release rollouts. Using on-demand deploy we can update API Express and Server Code instances one by one adding and removing nodes from balancing rules during these updates. Our users and their apps can use the backend services without any interruptions (100% uptime). This approach is shown in the image below.
Spikes from Specific Apps
There is another challenge. From time to time an app can execute a complicated Server Code script or invoke an API Express service and create a heavy load on the services extremely fast and unexpectedly. To handle this, we analyzed the behavior of services and designed custom monitoring scripts. The data from our custom monitoring scripts is parsed and analyzed. Based on the data we gathered, we provide CloudWatch monitoring with the required thresholds. Scaling policy (increase or decrease service group capacity) is launched according to these thresholds. The result of this on-demand extra instance deployment is illustrated on the diagram below:
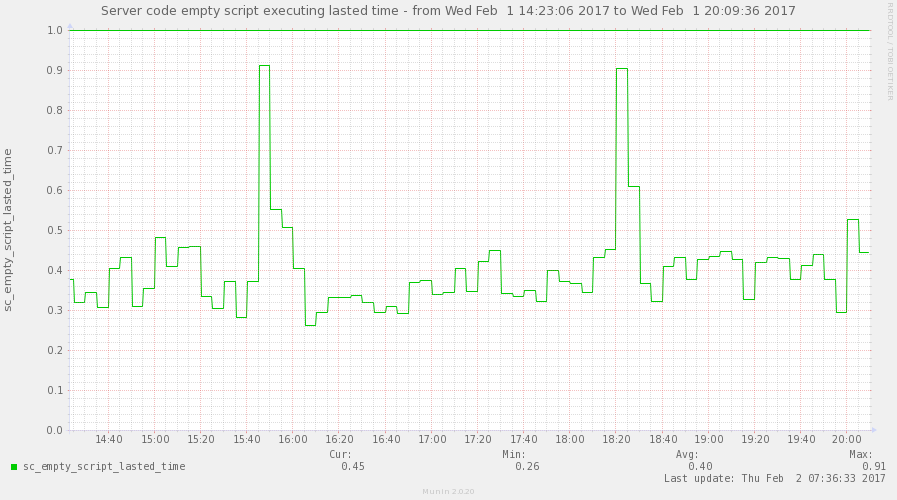
As you can see in this diagram, Server Code script response time skyrocketed twice during the period. But, the platform didn’t wait until the response time became critically slow. The Auto Scaling policy received the threshold metric value and a new extra Server Code node was deployed and added to balancing scheme immediately.
Some Server Code scripts were executed on this new deployed instance. Response time for the Server Code scripts returned back to an average level. Users and their apps were not impacted. When the incoming load returned to the forecast level, an Auto Scaling policy received these metrics and the extra node was removed from the balancing scheme and terminated.
We constantly analyze, optimize, and improve our monitoring scripts. As you can probably guess, this work is never complete. We try to find new and better metrics and criteria to optimize on-demand deployment for Server Code and API Express services.
The main challenge is that we need to be able to predict possible issues in the production environment and react to them in time to avoid any service interruptions. The alternative is a possible downtime, slow response time, frustration for users — and that’s exactly what we try to avoid.